Anda telah mengoptimalkan situs web Anda untuk Google. Anda telah membangun backlink, menyempurnakan deskripsi meta, dan menaiki peringkat pencarian. Namun inilah kenyataan yang tidak nyaman: tidak ada yang menjamin Anda akan muncul ketika seseorang meminta rekomendasi ChatGPT di industri Anda.
Selamat datang di era Visibilitas AI — metrik yang dengan cepat menjadi sama pentingnya dengan peringkat pencarian organik Anda, meskipun bermain dengan aturan yang sepenuhnya berbeda.
- Mengapa peringkat di Google tidak menjamin visibilitas pada jawaban yang dihasilkan AI
- 5 KPI esensial untuk mengukur kehadiran merek Anda di pencarian berbasis AI
- Bagaimana alat visibilitas AI benar-benar mengumpulkan data dan bias yang diperkenalkan oleh masing-masing metode
- Sebuah kerangka sampling praktis untuk mengukur visibilitas AI tanpa gelar statistika
- Cara menafsirkan variabilitas keluaran LLM dan membangun dashboard yang mencerminkan kenyataan
Apa itu “AI Visibility” (dan Apa yang Perlu Diukur)
Dave Minifie, Terakeet”>Wawasan Ahli: “Apapun konten Anda dibaca, dikutip, atau dirujuk oleh AI generatif, visibilitas AI sekarang menjadi titik pengaruh pertama bagi banyak merek. Agar tetap kompetitif, konten Anda harus dibangun untuk visibilitas itu.” — Dave Minifie, Terakeet

AI visibility mengukur seberapa mudah ditemukan, dikenali, dan direpresentasikan secara akurat merek Anda di dalam alat pencarian berteknologi AI dan model bahasa besar. Kita berbicara tentang platform seperti ChatGPT, Gemini, Claude, Perplexity, dan Google AI Overviews. Saat konsumen mengajukan pertanyaan terkait industri Anda pada salah satu sistem tersebut, AI visibility menentukan apakah merek Anda muncul dalam jawaban—dan bagaimana merek Anda digambarkan.
Peralihan yang sedang terjadi sekarang signifikan. Pada 2025, 71% konsumen menggunakan alat AI untuk mencari informasi, dengan 14% melakukannya setiap hari. Merek yang muncul dalam jawaban yang dihasilkan AI melihat dampak yang terukur – halaman yang disebutkan dalam AI Overviews menerima 35% lebih banyak klik organik, dengan rujukan AI mengonversi sekitar 2–3x lebih tinggi daripada pencarian tradisional.
Beamtrace are emerging – they help teams quantify how often, and in what context, their brand shows up in these AI-generated answers.”>Itulah sebabnya platform visibilitas AI khusus seperti Beamtrace sedang muncul—mereka membantu tim mengukur seberapa sering, dan dalam konteks apa, merek mereka muncul dalam jawaban yang dihasilkan AI.
Lantas apa bedanya visibilitas AI dengan metrik yang sudah Anda pantau?
📌 Apa yang Sebenarnya Dikutip? (Sinyal Konten)
Inilah pertanyaan krusial: jika peringkat Google tidak memprediksi AI Visibility, apa yang memprediksi? Jawabannya terletak pada memahami konten apa yang benar-benar dihargai sistem AI.
Penelitian yang menganalisis jutaan kutipan AI mengungkap lima sinyal dominan yang membedakan halaman yang dipilih AI untuk dikutip dari yang diabaikan.
1. Kebaruan (Paling Krusial)
Konten yang dirujuk AI 25,7% lebih segar daripada konten yang muncul di hasil pencarian Google organik tradisional. Ini tidak halus — itu adalah preferensi struktural yang tertanam dalam cara kerja sistem AI.
Angka-angka ini menceritakan kisah yang kuat:
- ChatGPT mengutip halaman yang diperbarui dalam 30 hari terakhir sebanyak 76,4% dari waktu
- Gemini menunjukkan preferensi kesegaran paling kuat, dengan kepadatan tertinggi pada konten sangat baru.
- Perplexity menjaga keseimbangan konten segar (berusia beberapa minggu) dan materi relatif lebih lama (berusia bertahun-tahun).
2. Struktur (Dampak Langsung Tertinggi)
Di antara semua sinyal di halaman, struktur adalah prediktor tunggal terkuat untuk kutipan ChatGPT.
Penelitian dari hampir dua juta sesi menemukan bahwa cuplikan jawaban ada pada 86,8% halaman yang menerima rujukan ChatGPT, dibandingkan hanya 13,2% halaman yang tidak memiliki cuplikan jawaban maupun wawasan eksklusif.
Begini bentuk kapsul jawaban:
- 1–2 kalimat jawaban langsung untuk pertanyaan di bagian atas halaman (sebelum penjelasan)
- Tautan minimal di teks kapsul (tautan eksternal terutama membatasi ekstraksi)
- Bagian yang jelas dan berdiri sendiri yang bisa di-quote tanpa membaca konteks sekitar
Tambahan sinyal struktural yang penting:
- Daftar dan tabel (lebih mudah diekstrak AI) menduduki peringkat lebih tinggi daripada paragraf berprosa
- Header H2 yang membagi konten menjadi potongan yang mudah dipindai meningkatkan peluang kutipan
- Poin-poin berisi bukti padat (data, statistik, rujukan) bisa diekstrak dengan jelas
3. Otoritas & E-E-A-T (Dioperasionalisasikan Berbeda dari SEO)
E-E-A-T (Pengalaman, Keahlian, Kewenangan, Kepercayaan) tetap penting untuk AI, tetapi wujudnya berbeda dibandingkan dengan pencarian Google.
Apa yang Diprioritaskan Sistem AI:
- Penulis bernama dan terlihat mengungguli halaman korporat tanpa identitas; byline penulis dengan halaman penulis khusus secara signifikan meningkatkan sitasi
- Volume pencarian merek (bukan backlink) adalah prediktor nomor 1 sitasi AI dengan korelasi 0.334, lebih kuat daripada backlink tradisional pada 0.37
- Kehadiran Multi-platform: Merek yang hadir di 4+ platform online 2,8x lebih mungkin muncul dalam respons ChatGPT
- Isyarat Konsistensi: Penyebutan merek, sitasi, dan referensi entitas yang konsisten di seluruh web meningkatkan kepercayaan
4. Data Asli atau Milik Sendiri (Pembeda Kedua Terkuat)
Setelah kapsul jawaban, data asli adalah prediktor terkuat sitasi ChatGPT.
Dampaknya signifikan:
- Menambahkan statistik meningkatkan visibilitas AI sebesar 22%
- Menambahkan kutipan meningkatkan visibilitas sebesar 37%
- Riset asli, dataset milik sendiri, atau hasil pilot secara signifikan meningkatkan peluang sitasi
5. Kepadatan Bukti (Klaim yang Didukung di Mana-mana)
Teks yang kaya data, statistik, dan sitasi mendapatkan skor lebih tinggi daripada pernyataan umum atau konten berbasis opini.
Sistem AI menilai setiap potensi kutipan berdasarkan kemudahan ekstraksi. Suatu bagian yang mencakup verifikasi (keselarasan dengan beberapa sumber tepercaya) dan data poin spesifik jauh lebih mungkin untuk dikutip daripada konten yang lebih samar.
Struktur yang Menang:
- Poin data spesifik dengan sumber yang dikaitkan
- Rujukan pendukung (menunjukkan kesepakatan di antara sumber ahli)
- Contoh nyata lebih baik daripada contoh hipotetis
- Klaim yang dapat diverifikasi lebih penting daripada pernyataan aspiratif
🌐 Pola Spesifik Platform: Mengapa Strategi Halaman Anda Tak Bisa Satu Ukuran untuk Semua
Berikut wawasan penting: ChatGPT, Perplexity, Gemini, dan Google AI Overviews masing-masing mengutip jenis konten yang berbeda.
ChatGPT sangat bergantung pada data pelatihan dan hasil pencarian Bing. Ia memprioritaskan kedalaman teknis, konten terkini, dan publikasi yang luas. Wikipedia mewakili sekitar 47,9% dari sitasinya; platform ini menyebut merek 3,2x lebih sering daripada memberi tautan.
Perplexity menjalankan pencarian waktu-nyata dan memfavoritkan jawaban multi-sumber, memberi Anda lebih banyak peluang untuk tampil sebagai salah satu sumber yang dikutip. Reddit memimpin dengan 46.7% kutipan; platform ini lebih menyukai URL terbaru dan ceruk yang lebih kecil serta belum banyak dimanfaatkan.
Gemini memprioritaskan konten milik merek dan menunjukkan preferensi terkuat untuk materi yang segar. Ini paling mirip dengan peringkat pencarian Google, tetapi dengan bobot otoritas yang berbeda.
Google AI Overviews mempertahankan keselarasan terdekat dengan peringkat pencarian konvensional: 93,67% menyebut setidaknya satu hasil organik top-10, dengan 76% kutipan berasal dari 10 teratas. Namun, 24% kutipan dari luar 100 teratas menunjukkan bahwa markup skema (FAQPage, Article, NewsArticle) dan konten terstruktur memiliki arti yang berbeda di sini.
Halaman yang sering dirujuk oleh ChatGPT mungkin menunjukkan kutipan Perplexity yang minimum. Anda perlu visibilitas di beberapa platform, yang berarti memahami logika pengambilan data yang berbeda. Inilah mengapa strategi multi-platform mengalahkan taruhan pada satu platform saja.
🔍 Cara Visibilitas AI Berbeda dari SEO dan PR
Bayangkan begini: SEO fokus pada posisi peringkat dan rasio klik-tayang di halaman hasil mesin pencari. PR menekankan penyebutan di media dan liputan pers. Visibilitas AI membutuhkan sesuatu yang sama sekali berbeda: merek Anda perlu disebutkan, disitir, atau diberi tautan dalam jawaban yang dihasilkan AI di berbagai platform.
Inilah mengapa perbedaan itu penting: penelitian menunjukkan bahwa hanya 12% URL yang dikutip oleh asisten AI berada di peringkat 10 teratas Google untuk kueri yang sama – dan lebih dari 80% tidak berada di peringkat mana pun di Google Top 100. Ini mengungkap wawasan mendasar: meskipun Google AI Overviews mengikuti peringkat pencarian tradisional (76% kutipan berasal dari halaman Top 10), asisten AI mandiri seperti ChatGPT dan Gemini menggunakan logika pengambilan yang berbeda, sering kali lebih memilih halaman yang peringkatnya lebih rendah di Google tetapi muncul secara konsisten di berbagai variasi kueri.
Dua dunia itu saling tumpang tindih, tetapi keduanya jauh dari identik.
KPI Visibilitas AI Inti (Dasbor Minimum)
Sebelum meningkatkan visibilitas AI, Anda perlu mengukurnya. Lima metrik ini menjadi fondasi dari setiap dasbor visibilitas AI.
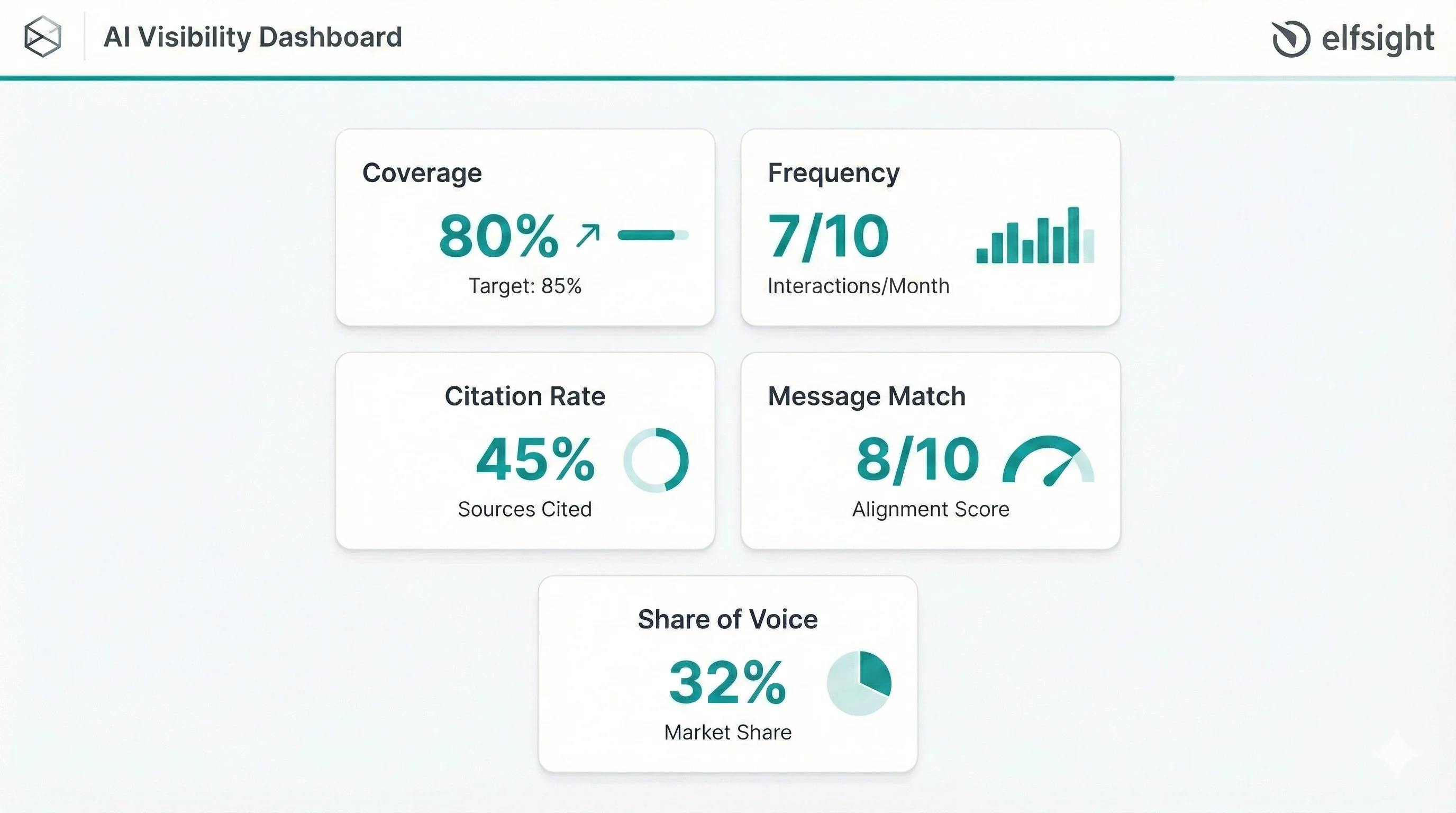
Cakupan
Cakupan menunjukkan seberapa sering merek Anda muncul untuk kueri tingkat kategori. Hitung sebagai persentase: (Jumlah kueri di mana Anda muncul) ÷ (Total kueri relevan) × 100.
Saat Cakupan Menyesatkan Anda
Tingkat cakupan 80% terdengar mengesankan, hingga Anda menyadari itu tersebar hanya di lima topik niche sementara pesaing mendominasi kueri dengan volume tinggi. Selalu beri bobot cakupan berdasarkan pentingnya kueri, bukan hanya persentase mentah.
Frekuensi
Frekuensi mengukur berapa kali merek Anda disebut dalam beberapa kali menjalankan prompt yang sama. Inti utamanya adalah melacaknya sebagai rentang (misalnya terlihat pada 3–5 dari 10 jalankan) daripada menganggap satu hasil sebagai kebenaran.
Ketika Frekuensi Menyesatkan Anda
Satu sebutan sukses yang tersembunyi dalam daftar yang didominasi pesaing terlihat seperti kemenangan di atas kertas. Namun jika Anda disebutkan sekali sementara tiga pesaing direkomendasikan berulang kali, “kemenangan” itu tidak berarti banyak dalam praktiknya.
Laju Sitasi
Tingkat sitasi menangkap persentase jawaban yang dihasilkan AI yang menyertakan tautan atau atribusi ke halaman atau domain spesifik Anda. Pemasar cerdas juga melacak posisi sitasi – disebutkan pertama memiliki bobot jauh lebih besar daripada muncul di akhir daftar.
Kapan Laju Kutipan Menyesatkan Anda
Dikutip terakhir dalam daftar sumber yang panjang sama pentingnya dengan menjadi rekomendasi utama jika Anda hanya melacak data biner “dikutip atau tidak”. Keduanya terdaftar sebagai sitasi, tetapi dampaknya tidak bisa lebih berbeda.
Akurasi Penempatan
Metrik ini menilai seberapa dekat deskripsi AI terhadap merek Anda dengan posisi yang Anda targetkan. Kebanyakan tim memberi skor pada skala 1–10 berdasarkan akurasi, nada, dan kelengkapan.
Ketika Kesesuaian Pesan Menyesatkan
AI mungkin menggambarkan produk Anda secara akurat tetapi menempatkan pesaing sebagai opsi “terbaik” dalam kalimat yang sama. Anda disebutkan dengan benar, tetapi Anda tetap kalah dalam perang rekomendasi.
Pangsa Suara (SOV) dalam Jawaban AI
Share of Voice menghitung sebutan merek Anda dibagi dengan total sebutan Anda ditambah pesaing, dinyatakan sebagai persentase. Metrik ini mengungkap variasi antar platform yang sangat signifikan: satu merek dicatat SOV 24% di satu platform tetapi kurang dari 1% di platform lain.
Saat SOV Menyesatkan Anda
Pangsa suara 30% tidak berarti apa-apa jika kueri memiliki niat pencarian rendah atau nilai bisnis minim. Selalu hubungkan SOV dengan relevansi komersial kueri yang Anda ukur.
🚀 Contoh Dunia Nyata: Lonjakan Visibilitas AI Ramp
Tantangan
Ramp, perusahaan fintech B2B yang mengkhususkan diri pada otomasi Accounts Payable, menghadapi krisis visibilitas dalam jawaban yang dihasilkan AI. Meskipun peringkat mereka baik di Google untuk kata kunci tradisional, mereka hampir tidak terlihat ketika sistem AI menjawab pertanyaan pembeli.
Pengukuran awal: Hanya 3,2% visibilitas AI di kategori inti mereka. Pesaing berada 2–5x lebih tinggi di ChatGPT, Perplexity, dan Gemini. Ramp kehilangan pangsa perhatian tepat saat 71% pembeli memulai riset mereka dengan pencarian AI.
Strategi
Ramp menggunakan Profound’s Answer Engine Insights untuk membongkar apa yang sebenarnya dirujuk AI. Alih-alih menebak, mereka mengidentifikasi jenis konten dan topik yang muncul dalam jawaban yang dihasilkan AI:
- Studi kasus berfokus otomasi (bukan halaman produk umum)
- Konten perbandingan perangkat lunak dengan kerangka evaluasi terstruktur
- Kepemimpinan pemikiran terkait tren AP (topik-topik yang terlewat riset SEO tradisional)
- Bagian FAQ yang menjawab kriteria evaluasi sistem AI
Mereka secara strategis membuat dua halaman berdampak tinggi yang langsung menanggapi sinyal-sinyal ini. Alih-alih konten luas, mereka fokus pada pertanyaan pembeli berniat tinggi yang digunakan sistem AI untuk menyaring opsi.
Hasil (30 Hari)
| Metrik | Sebelum | Sesudah | Perubahan |
|---|---|---|---|
| Visibilitas AI | 3.2% | 22,2% | ↑ 7x |
| Peringkat Kompetitif (Kategori AP) | Ke-19 | ke-8 | ↑ 11 posisi |
| Jumlah Kutipan | ~40 | 300+ | ↑ 7,5x |
| Pangsa Sitasi | 8,1% | 7.5% | Paritas Kompetitif |
| Halaman dengan sitasi terbanyak | N/A | 2 halaman baru mendominasi | Sinyal Otoritas Terbaru |
Wawasan Utama
Peningkatan 7x Ramp dalam hanya 30 hari membuktikan dua hal penting:
- Visibilitas AI bukan soal kebetulan — ini soal memahami mekanisme platform.
- Visibilitas AI bisa bergerak jauh lebih cepat daripada SEO tradisional karena sistem AI memperbarui indeks dan pola sitasi mereka lebih sering daripada algoritme peringkat Google.
Perusahaan itu berpindah dari peringkat ke-19 ke peringkat ke-8 di kategori kompetitif mereka karena berhenti mengoptimalkan faktor peringkat Google dan mulai mengoptimalkan kriteria evaluasi mesin jawaban AI — pendekatan yang secara fundamental berbeda.
Cara Alat Visibilitas AI Mengumpulkan Data (dan Mengapa Itu Penting)
Inilah hal penting yang perlu dipahami: tidak ada alat yang memiliki akses langsung ke bagaimana model AI menilai sumber secara internal. Setiap alat visibilitas bekerja dengan mensimulasikan perilaku pengguna dan menyimpulkan visibilitas dari keluaran. Metode yang digunakan masing-masing alat memperkenalkan bias yang berbeda, jadi memahami bagaimana data Anda dikumpulkan membantu Anda menafsirkannya dengan benar.
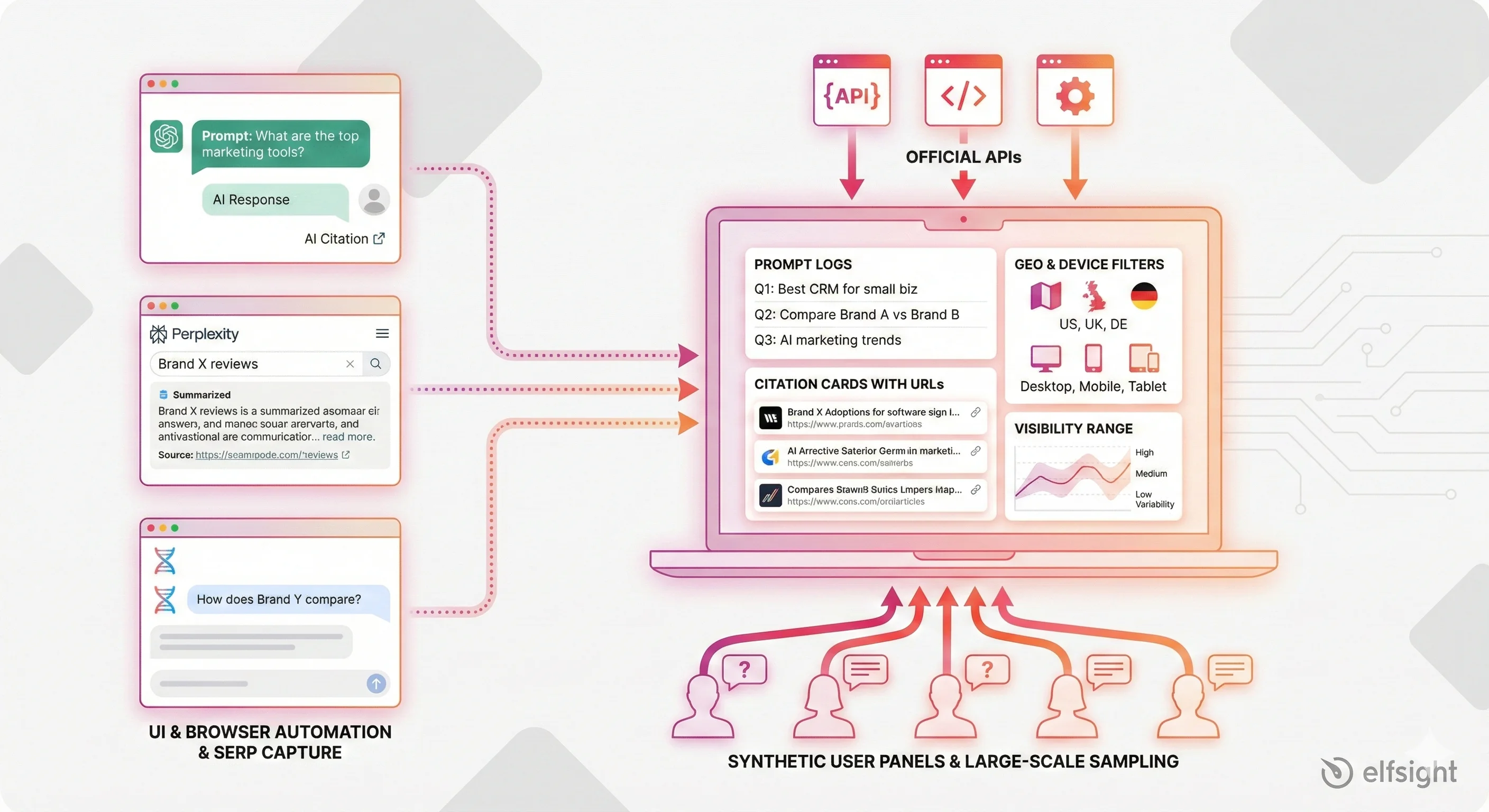
Otomatisasi UI / Peramban
Alat seperti Peec AI dan OtterlyAI menggunakan kerangka otomasi peramban (Puppeteer atau Playwright) untuk mengirim prompt ke ChatGPT, Perplexity, atau Gemini dan menangkap responsnya. Mereka biasanya mengambil snapshot harian dari kumpulan prompt.
Kekuatan utamanya adalah keaslian—Anda melihat persis apa yang dilihat pengguna nyata. Keterbatasannya: alat ini tidak bisa berjalan pada skala besar karena pembatasan permintaan otomatis dari platform. Anda juga hanya menangkap apa yang terlihat dalam respons, bukan skor peringkat internal.
API Resmi vs. API Proksi
Beberapa platform seperti Perplexity menampilkan data kutipan terstruktur melalui API resmi. Kebanyakan platform lain memerlukan alat untuk membongkar atau mengekstrak keluaran. API resmi memberikan data yang lebih andal dan terstruktur, tetapi adopsi vendor lambat, dan Anda tetap tidak memiliki wawasan mengenai seluk-beluk model.
Penangkapan SERP & Gambaran AI
Gambaran AI Google muncul langsung di hasil pencarian sekitar 50% kueri per tengah 2025. Alat seperti SEOmonitor menangkap seluruh teks AI Overview, termasuk konten yang tersembunyi di balik bagian “load more”.
Panel & Pengguna Sintetis
Platform perusahaan seperti Profound dan Semrush menjalankan ribuan prompt per bulan dengan variasi frasa, lokasi, dan model. Pendekatan ini memberi Anda keandalan statistik dan mengungkap pola variabilitas. Kelemahannya? Biayanya mahal, dan meskipun ribuan prompt hanya mewakili sebagian kecil dari kueri pengguna sesungguhnya.
Daftar Periksa Keandalan Data
Tak semua data visibilitas AI layak dipercaya. Sebelum bertindak berdasarkan metrik apa pun, jalankan sumber data Anda melalui daftar periksa ini:
| Kriteria | Mengapa Ini Penting | Tanda Bahaya |
|---|---|---|
| Frekuensi Pengambilan Sampel | Eksekusi harian menangkap fluktuasi; eksekusi bulanan melewatkan perubahan cepat | “Pembaruan triwulan” untuk pasar yang aktif |
| Pengulangan per prompt | Beberapa kali percobaan mengungkap variabilitas alami dibandingkan dengan kesalahan | Satu kali eksekusi = kebisingan tinggi |
| Cakupan Geografis/Perangkat | Hasil bervariasi berdasarkan lokasi dan jenis perangkat | Hanya bahasa Inggris AS yang dilaporkan |
| Versi Prompt | Pembaruan model mengubah jawaban; riwayat versi sangat penting | “Prompt terbaru” tanpa catatan perubahan |
| Transparansi Data | Bisakah Anda melihat tangkapan layar mentah atau mengekspor keluaran secara lengkap? | Hanya dasbor bermerk, tanpa data mentah |
| Ekstraksi Kutipan | Apakah URL diurai dengan benar dari respons? | Hanya menghitung sebutan, bukan tautan |
| Pelaporan varians | Bagaimana rentang/tingkat kepercayaan dinyatakan? | Hanya estimasi titik tunggal |
Kesalahan Umum yang Perlu Dihindari
Hindari kesalahan berikut yang bisa membuat Anda menarik kesimpulan keliru:
- Metrik vanity: Menghitung setiap sebutan tanpa memeriksa konteks atau posisinya
- Terlalu sedikit prompt: Kurang dari 10–20 prompt per topik menciptakan kebisingan statistik yang tinggi
- Pengujian hanya berdasarkan merek: Kueri seperti “terbaik X untuk Y” mengungkap jauh lebih banyak daripada pencarian merek langsung
- Mengabaikan perubahan versi model: ChatGPT secara teratur menggeser pola sitasi, dan banyak alat tidak menandai saat hal ini terjadi
- Merespons berlebihan terhadap perubahan satu kali jalankan: Variabilitas adalah normal dalam keluaran LLM – lacak rentang, bukan potret individual
Mengatasi Variasi Jawaban LLM (Pastikan Pelacakan Secara Statistik Real)
Minta ChatGPT pertanyaan yang sama dua kali dan Anda mungkin mendapatkan jawaban yang berbeda. Ini bukan bug, ini bagaimana model bahasa besar bekerja. Memahami mengapa jawaban bisa bervariasi membantu Anda membangun pendekatan pengukuran yang memperhitungkan kenyataan ini.
Mengapa Jawaban AI Berubah
Suhu dan Keacakan
LLMs menggunakan pengambilan sampel probabilistik untuk menghasilkan jawaban. Pengaturan temperatur rendah (sekitar 0,2) cenderung menghasilkan jawaban yang dapat diprediksi. Pengaturan sedang (0,7, default ChatGPT) seimbang antara kreativitas dan koherensi. Pengaturan tinggi (1,2+) meningkatkan ketidakpastian. Menariknya, penelitian menunjukkan perubahan temperatur dari 0,0–1,0 tidak secara statistik memengaruhi akurasi pada tugas pemecahan masalah, meskipun meningkatkan keragaman keluaran.
Pembaruan Model
OpenAI, Google, dan Anthropic secara rutin meluncurkan versi model baru. Pembaruan ini dapat secara drastis mengubah pola sitasi: o3 mengalami halusinasi sebesar 33% pada satu tolok ukur, sedangkan o4-mini melonjak menjadi 48%. Perplexity menyegarkan indeks pengambilan datanya setiap bulan.
Perubahan Pengambilan Data
Indeks yang mendukung jawaban AI terus diperbarui. Bobot kesegaran bergeser. Sumber baru akan diindeks. Halaman yang pernah dikutip bulan lalu bisa turun jika pesaing yang lebih baru mempublikasikan konten serupa.
Frasa Prompt
“Best X for Y” memicu hasil yang berbeda dibandingkan dengan “Top X for Y” atau “Perbandingan X.” Niat, spesifikasi, dan cara penyajian semuanya mempengaruhi sumber mana yang dikutip.
Lokasi, Bahasa, dan Waktu
Gemini menunjukkan hasil yang berbeda di AS dibandingkan dengan Inggris. Permintaan yang sensitif waktu terkait berita atau harga berfluktuasi sepanjang hari.
Intervensi Keamanan
Kebijakan platform membatasi topik tertentu. Pedoman pengaman merek khusus dapat membayangi jawaban tanpa sinyal jelas bahwa penyaringan telah terjadi.
Model Mental yang Tepat
Tetapkan “visibilitas nyata” sebagai probabilitas dari banyak iterasi, bukan satu hasil saja. Jika merek Anda muncul di 3 dari 10 percobaan, visibilitas sebenarnya sekitar 30%, bukan ya/tidak biner.
Model Sampling Praktis untuk Pemasar
Anda tidak perlu gelar statistik untuk mengukur visibilitas AI dengan benar. Berikut pendekatan minimal yang memberi data andal tanpa kompleksitas yang berlebihan.
Dasar-dasar
- Prompt per topik: Uji 10–20 pertanyaan non-merek per area topik (seperti “alat terbaik untuk pemasaran email” atau “cara memilih platform analitik”)
- Pengulangan per prompt: Jalankan setiap prompt 3–5 kali pada model yang sama, pada hari yang sama, untuk menangkap variabilitas alami
- Ritme: Mingguan untuk pasar yang bergerak cepat (AI, SaaS, berita); bulanan untuk kategori yang stabil
- Ekspresi: Lapor rentang, bukan poin tunggal: “Muncul dalam 3–5 dari 10 percobaan” lebih akurat daripada “visibilitas 30%”
Membaca Hasil Anda
Jika Anda muncul pada 8 dari 10 percobaan secara konsisten, Anda memiliki visibilitas yang stabil. Jika Anda berfluktuasi antara 1–7 percobaan, visibilitasnya tidak stabil – cari tahu penyebabnya. Musiman, aktivitas pesaing, dan pembaruan model adalah dugaan umum.
Cara Melaporkan Variabilitas di Dashboard
Buat dashboard Anda untuk menampilkan:
- Rentang Visibilitas: Minimum/Median/Maksimum di seluruh klaster prompt Anda
- Skor Konsistensi: Persentase perulangan di mana Anda muncul (50% konsistensi = 5 dari 10 kali dijalankan)
- Arah tren: Tampilkan hanya “↑ +2 poin per minggu-ke-minggu” jika perubahan bertahan selama 3+ minggu
Kesalahan Dashboard yang Perlu Diperhatikan
Latih tim Anda untuk waspada terhadap kesalahan pelaporan berikut:
- Merespons berlebihan terhadap fluktuasi satu jalankan
- Hanya menggunakan kueri bermerek, bukan kueri berorientasi permintaan
- Mengabaikan konteks pesaing (muncul di 1 dari 10 percobaan berarti sedikit jika pesaing Anda muncul di 9 dari 10 percobaan)
- Tidak memperhitungkan pembaruan model yang terjadi selama jendela pengukuran
Keamanan Merek & Pemantauan Halusinasi
Visibilitas AI yang lebih tinggi itu bagus, asalkan AI tidak mengatakan hal yang salah tentang merek Anda. Permukaan risiko ini memerlukan perhatian pemantauan yang sama dengan peningkatan visibilitas Anda.
Mengapa Keamanan Merek Penting: Preseden Air Canada
Pada akhir 2024, chatbot Air Canada menciptakan kebijakan diskon “bereavement fare” yang tidak ada. Ketika seorang pelanggan menanyakannya, bot tersebut mengonfirmasi kebijakan itu. Pelanggan memesan berdasarkan rekomendasi chatbot — dan Air Canada menolak untuk menghormati kebijakan yang dibuat itu. Kasus ini diajukan ke tribunal, yang memutuskan bahwa Air Canada harus menghormati tawaran chatbot meskipun itu palsu. Maskapai menghadapi krisis reputasi dan potensi tanggung jawab di semua kasus serupa.
Ini bukan kasus terisolasi. Ketika sistem AI mengalami halusinasi tentang merek Anda—membuat fitur, harga yang salah, kebijakan palsu, atau salah mengaitkan kekuatan pesaing pada Anda—biayanya nyata: kebingungan pelanggan, eskalasi dukungan, peluang yang hilang, dan risiko hukum.
KPI Keamanan Merek: Penyebutan Negatif atau Salah
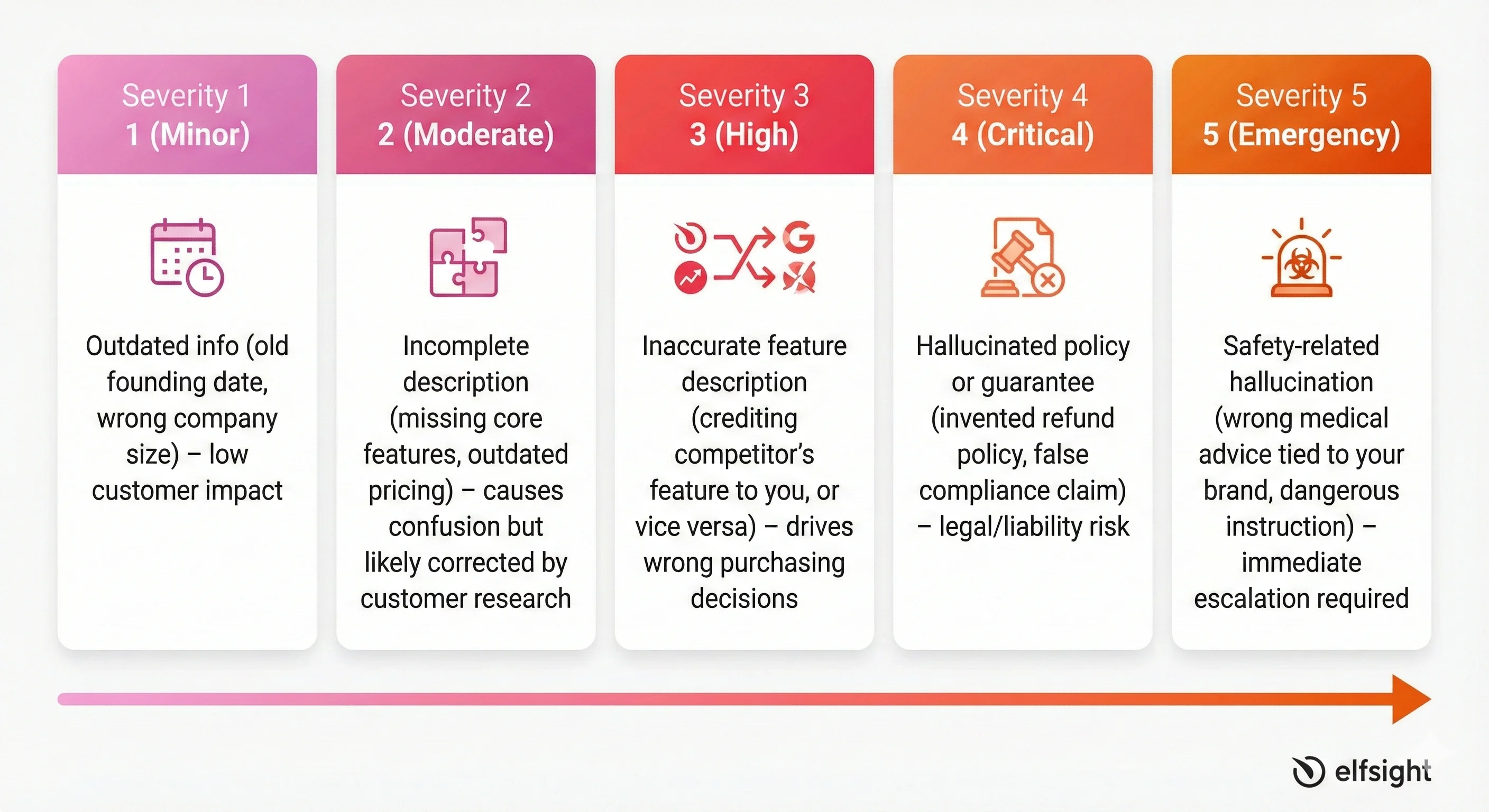
Metrik ini melacak deskripsi tidak akurat tentang merek Anda di berbagai sistem AI. Nilai tiap kejadian pada skala keparahan 1–5:
- Tingkat Keparahan 1 (Kecil): Informasi usang
- Keparahan 2 (Sedang): Deskripsi tidak lengkap
- Keparahan 3 (Tinggi): Deskripsi fitur tidak akurat
- Keparahan 4 (Kritis): Kebijakan atau garansi yang diada-ada
- Keparahan 5 (Darurat): Halusinasi terkait keselamatan
Checklist Audit Keamanan Merek
Tambahkan ini ke rutinitas pemantauan mingguan Anda:
- Akurasi Harga – Apakah AI menampilkan harga Anda saat ini dengan benar?
- Deskripsi Fitur – Apakah kemampuan inti dideskripsikan secara akurat, atau apakah fitur-fitur dikaitkan secara keliru?
- Info Perusahaan – Tanggal pendirian, ukuran tim, lokasi, nama pemimpin, semuanya benar?
- Status Produk – Apakah produk yang sudah usang masih direkomendasikan?
- Klaim Ketersediaan – Pembatasan geografis atau platform benar? Tidak ada fitur fiktif?
- Akurasi Tautan – Apakah URL yang disebut benar-benar ada dan berisi informasi yang dirujuk?
- Atribusi Pesaing yang Keliru – Apakah fitur pesaing dikreditkan untuk Anda, atau fitur Anda untuk mereka?
Pertanyaan yang Sering Diajukan
Berapa lama waktu yang dibutuhkan untuk meningkatkan visibilitas AI?
Jenis konten apa yang paling efektif untuk visibilitas AI?
Seberapa sering sebaiknya saya mengukur visibilitas AI?
Bagaimana cara memulai visibilitas AI jika Anda pemula?
Apa bedanya visibilitas AI dengan SEO tradisional?
Langkah Selanjutnya
Sekarang Anda memahami apa itu AI visibility dan bagaimana mengukurnya, langkah selanjutnya sederhana: jalankan baseline Anda. Pilih 10–15 kueri berniat tinggi di kategori Anda, uji di ChatGPT, Perplexity, dan Gemini, dan catat di mana Anda muncul. Latihan 2–3 jam ini segera mengungkap peluang terbesar Anda.
Begitu Anda memiliki tolok ukur, pekerjaan sesungguhnya dimulai: pembuatan konten yang mengikuti pola jawaban AI, optimasi teknis untuk ekstraksi sitasi, dan pembangunan otoritas melalui PR dan kepemimpinan pemikiran. Kasus Ramp menunjukkan perubahan ini menghasilkan peningkatan visibilitas 7x dalam 30 hari – jauh lebih cepat daripada SEO tradisional.
Satu wawasan penting: ChatGPT, Perplexity, Gemini, dan Google AI Overviews masing-masing memberi peringkat sumber secara berbeda. Mengoptimalkan satu platform tidak otomatis membantu yang lain. Anda membutuhkan strategi lintas-platform yang memperhitungkan pola pengambilan data yang berbeda.
Merek-merek yang unggul dalam visibilitas AI saat ini tidak beruntung; mereka sengaja membangunkannya. Mereka memahami bagaimana setiap platform bekerja, mereka mengukur apa yang penting, dan mereka berputar dengan cepat. Itulah playbook-nya.